Overview

We present RoTri-Diff, a diffusion-based framework for bimanual imitation learning that centers on robot–object triadic interaction RoTri. By explicitly modeling and leveraging the relative 6D pose relations between the two arm end-effectors and the manipulated objects, it achieves stable performance on bimanual tasks requiring fine-grained coordination.
Method
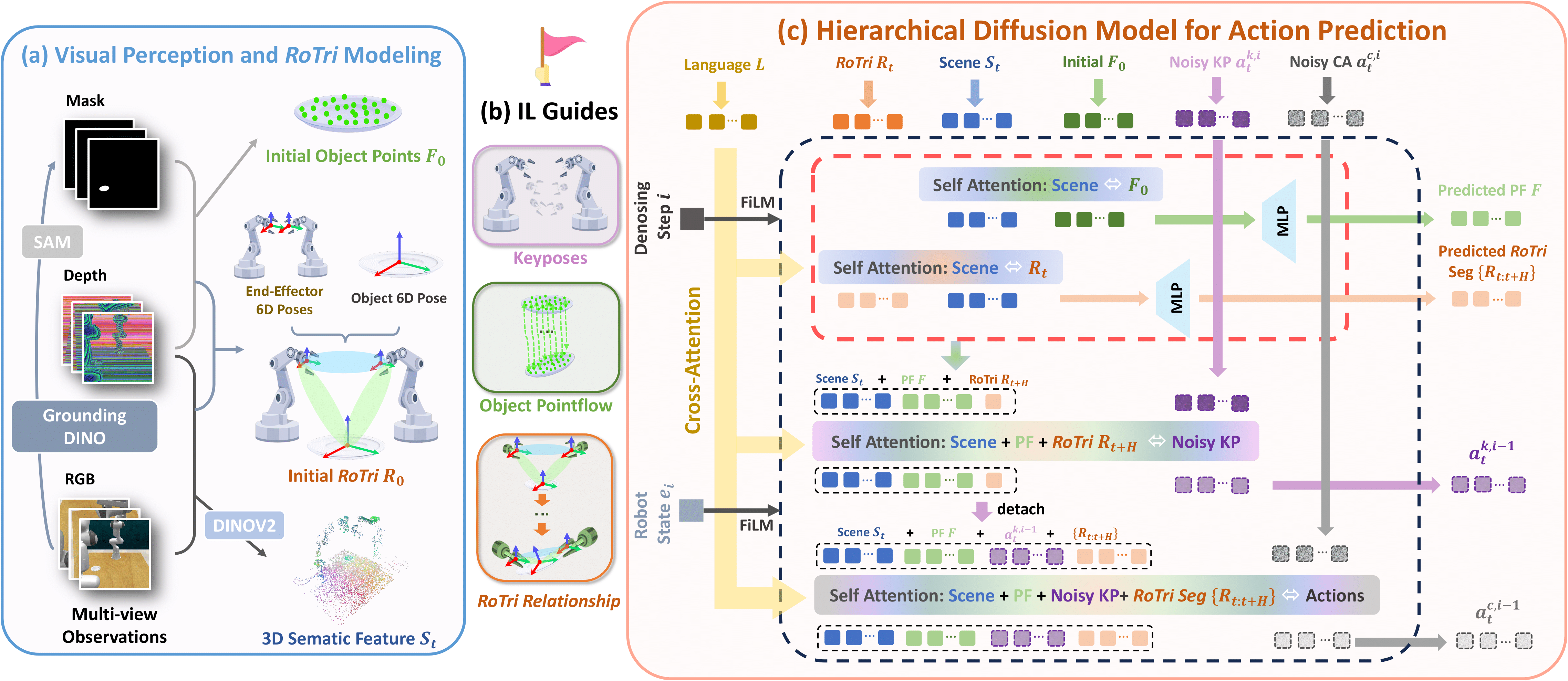
Overview of RoTri-Diff. (a) Visual Perception and RoTri Modeling: Extracting the initial object point cloud $F_0$, 3D semantic features $S_t$, and the initial RoTri representation $R_0$ from multi-view observations. (b) Imitation Learning Guidance Signals: Three complementary signals used for supervision: Keyposes, Object Pointflow, and the RoTri Relationship. (c) Hierarchical Diffusion Model: The model concurrently predicts object pointflow and autoregressively predicts a future RoTri segment. These predictions then serve as dynamic conditions to guide the denoising and generation of keyposes and continuous actions within a synergistic attention module.